|
Hi! I'm a third-year master student in Tsinghua University (Shenzhen International Graduate School), supervised by Prof. Yansong Tang. Before that, I received my bachelor's degree from the School of Computer Science in the Beijing University of Posts and Telecommunications in 2023. My currect research interest lies in Multimodal LLM and its applications. |

|
|
|

|
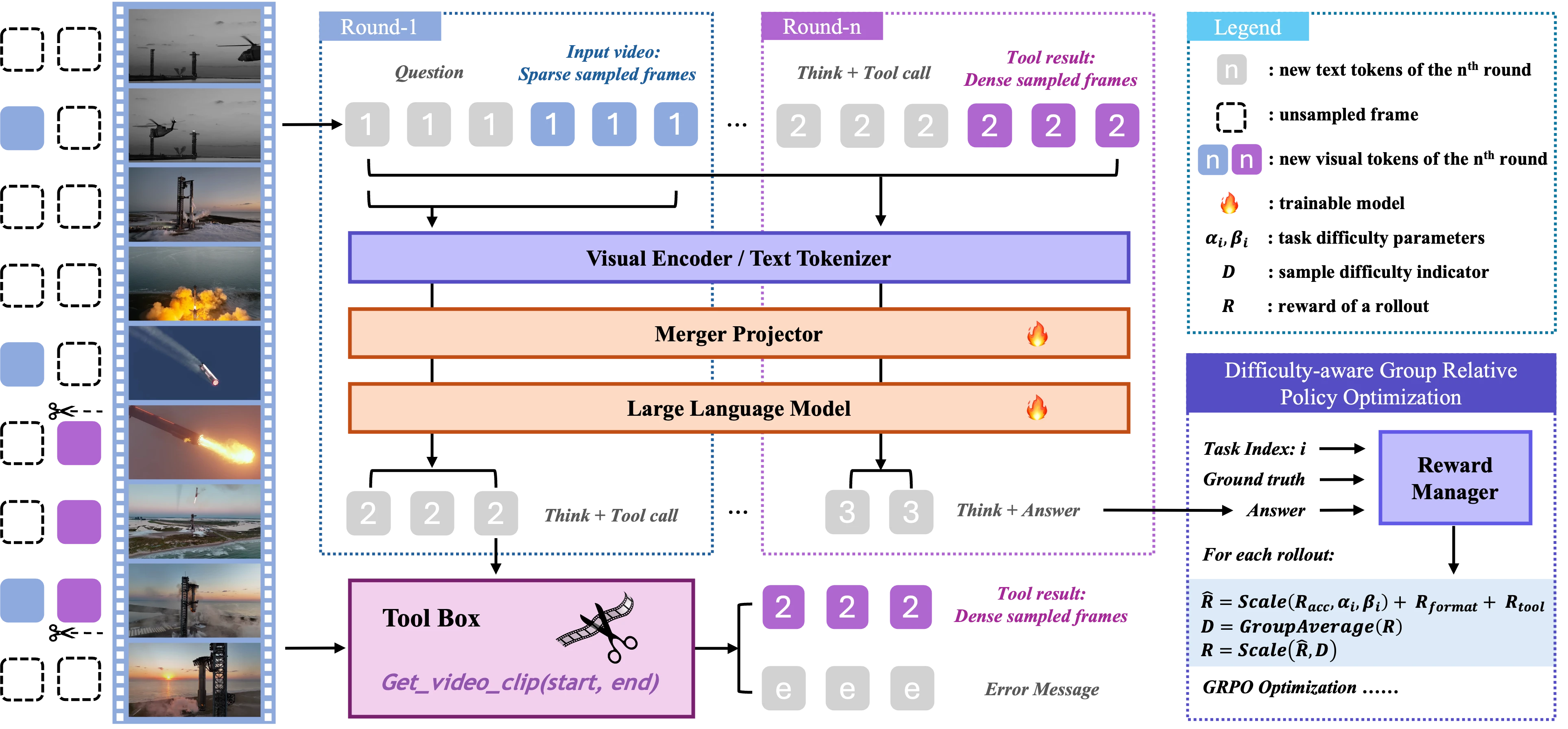
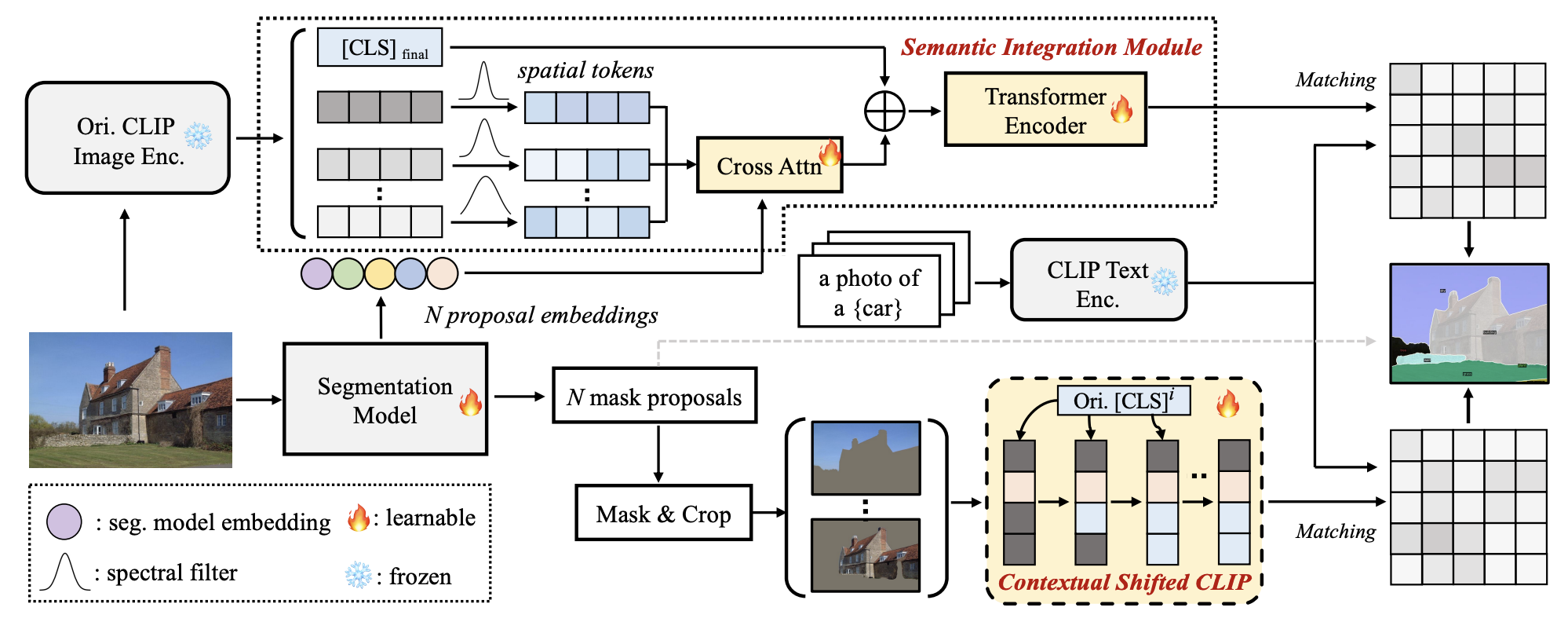
Sule Bai, Mingxing Li, Yong Liu, Jing Tang, Haoji Zhang, Lei Sun, Xiangxiang Chu, Yansong Tang arXiv Preprint, 2025 [Paper] [Code] [Project Page] 
|
|
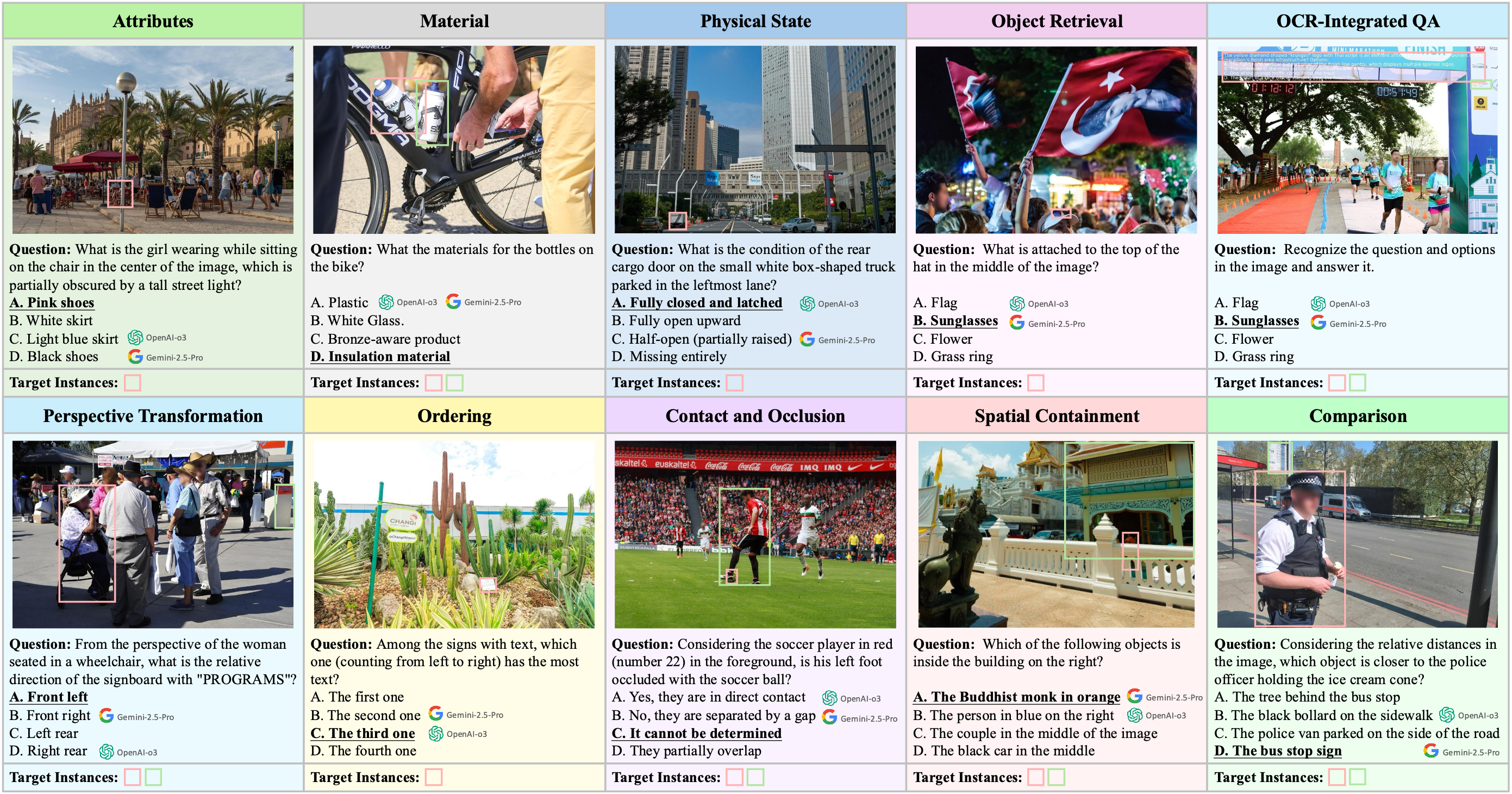
Haoji Zhang, Xin Gu, Jiawen Li, Chixiang Ma, Sule Bai, Chubin Zhang, Bowen Zhang, Zhichao Zhou, Dongliang He, Yansong Tang IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026 [Paper] [Code] 
|
|
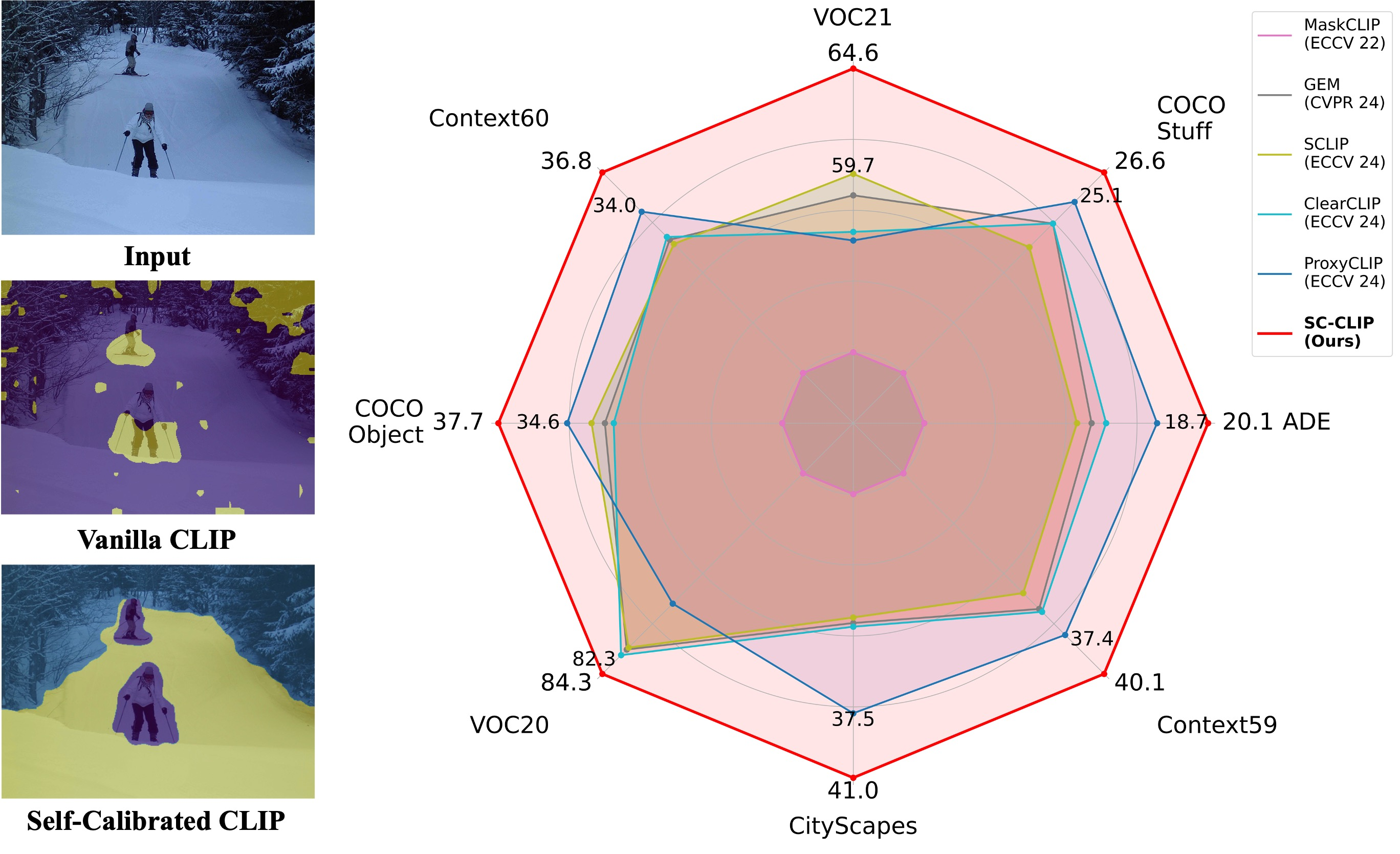
Haochen Wang, Xiangtai Li, Zilong Huang, Anran Wang, Jiacong Wang, Tao Zhang, Jiani Zheng, Sule Bai, Zijian Kang, Jiashi Feng, Zhuochen Wang, Zhaoxiang Zhang International Conference on Learning Representations (ICLR), 2026 [Paper] [Code] 
|
|
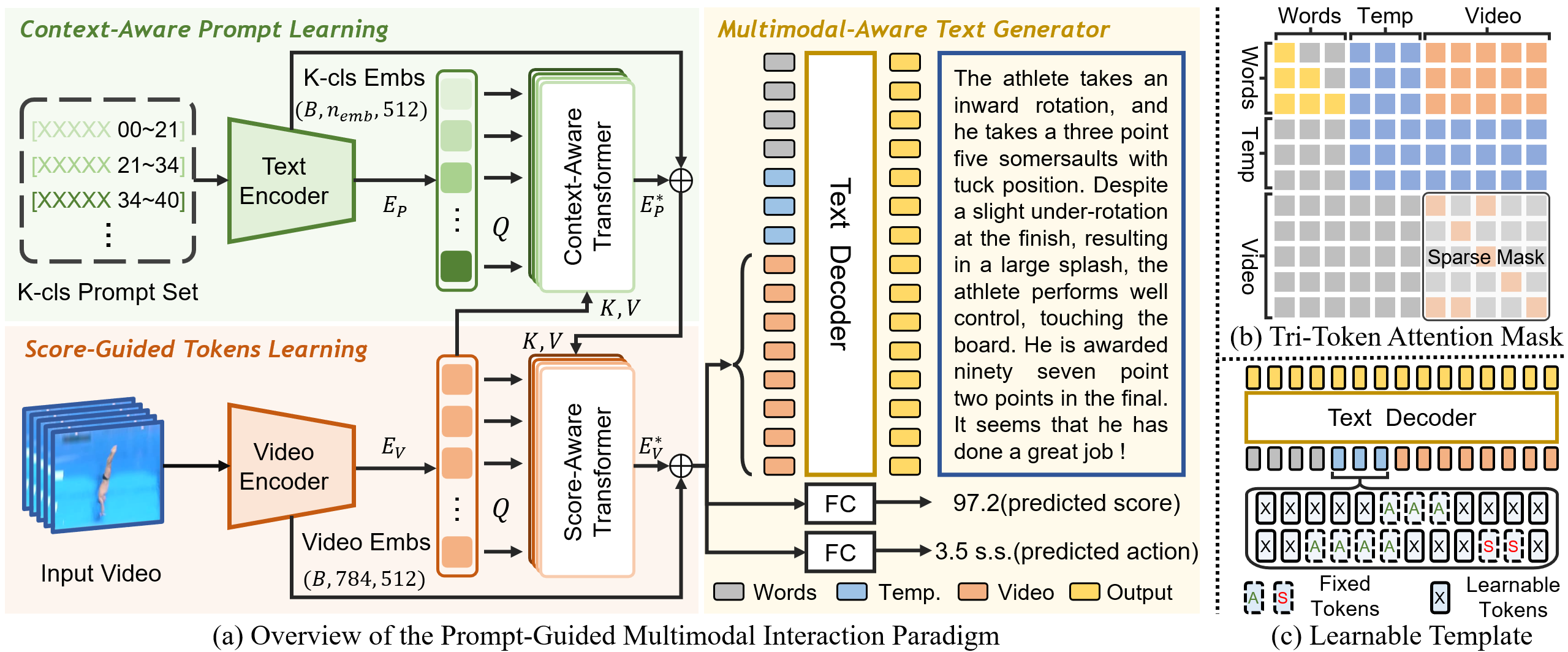
Sule Bai*, Yong Liu*, Yifei Han, Haoji Zhang, Yansong Tang, Jie Zhou, Jiwen Lu
* equal contribution
IEEE Transactions on Image Processing (TIP) (CCF-A, IF=13.7), 2025
[Paper] [IEEE] [Code] 
|
|
Sule Bai*, Shiyi Zhang*, Guangyi Chen, Lei Chen, Jiwen Lu, Junle Wang, Yansong Tang
* equal contribution
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
[Paper] [Code] 
|
|
Yong Liu*, Sule Bai*, Guanbin Li, Yitong Wang, Yansong Tang
* equal contribution
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
[Paper] [Code] 
|

|
Yong Liu*, Songli Wu*, Sule Bai*, Jiahao Wang, Yansong Tang
* equal contribution
IEEE/CVF International Conference on Computer Vision (ICCV), 2025
[Paper] |